
打破 MCU 的算力高牆:利用自動化特徵工程,在MCU上實現Edge AI

一、運用AI碰撞到物理的極限
從雲端轉為端點落地的起始
在過去的十年之間,AI人工智慧的發展主軸基本上都是圍繞著「更大、更深、更強」,我們習慣了在雲端使用擁有數億或甚至於數十億參數的巨型模型來處理自然語言或複雜影像應用。
然而,隨著人工智慧物聯網的爆發性成長,目前的戰場已經逐步的轉移。
現在的技術焦點,已經不再是誰能在雲端跑出更高的基準測試分數,而是誰能將 AI 的智慧成功植入到資源極度受限(記憶體跟效能較低)的MCU,這一塊我們稱之為端點智慧。
從工業 4.0 的預測性維護、智慧家庭的語音辨識甚至到穿戴式裝置的即時健康監測,這些應用場景對即時性、應用成本以及資料隱私這一塊,逐漸開始有被嚴苛要求。
將所有感測器數據上傳雲端分析已不再是唯一解方,在感測器的周邊直接進行運算成為了未來的趨勢。
資料量的限制以及遇到的硬體囚籠
然而,當資料科學家試圖將實驗室中的 AI 模型移植到嵌入式系統時,往往會撞上一堵厚實的牆,這堵牆就是物理資源上的上限。
典型的深度學習模型如同吞噬算力的巨獸,它們需要大量的RAM來儲存中間運算結果,以及龐大的Flash來存放各個模型的權重。
但現實世界中的MCU,其中的記憶體往往都是以KB或是MB為單位做計量,因此像是廣泛應用於馬達控制或家電的芯片,如果使用者試圖將未經優化的神經網絡硬塞進 MCU,就像是試圖將跑車的引擎裝進小型的自行車裡,不僅應用上不可行,更是對團隊中工程資源造成額外的浪費。
上述也說明了一個目前所遇到的矛盾,開發者渴望利用AI的精準度去改善應用的本質,增加產能或效率,但是卻無法承擔其的建置及運算成本。
關於資料分析以及模型的減法
要解決上面說的矛盾,我們發現已經不能去依賴硬體的無限制升級,而必須要回歸到資料分析的本質,這就像是一場關於減法的魔術一樣。
在嵌入式 AI 的開發中,模型裁剪以及所謂的特徵萃取的重要性會遠高於模型架構的堆疊。
首先,我們先針對資料分析的篩選以及模型的瘦身概念進行說明
- 資料分析的篩選:Raw Data中往往包含有90%以上的雜訊與冗餘資訊,真正的技術會是在於如何透過DSP與數學轉換運算,在進入神經網絡之前,就先將其中的無效資訊剔除。
- 模型的瘦身:透過移除神經網絡中貢獻度極低的連結或是神經元,我們可以在幾乎不犧牲準確率的前提下,大幅縮減模型的尺寸以及運算量。
即便上述這些概念聽起來十分的理想,但是在實作上卻是困難重重,這需要開發者同時具備數學直覺以及嵌入式工程的技術經驗。
通往Reality AI的道路
對於大多數企業而言,培養一支兼具這兩種跨領域技能的團隊成本極高且耗時。這正是需要我們重新思考整個開發流程的原因。如果有一套工具,能夠在數學層面上自動探索數據中的物理特徵,並自動執行高效率的模型裁剪,最終生成能直接在Renesas MCU上運行的優化代碼,那麼Edge AI的門檻將被大幅度的夷平。
這正是Renesas Reality AI介入的契機,它不只是一個建模工具,更是一個將”複雜資料分析”轉化為”精簡嵌入式程序”的自動化橋樑。
接下來,我們將深入探討如何透過這種獨特的方法,在極致受限的硬體上實現驚人的 AI 效能。
二、資料分析以及模型的瘦身
非視覺感測器的訊號處理
當大眾或客戶端談論 AI 時,腦海中浮現的往往是電腦視覺(Vision),像是辨識貓狗或人臉,然而,在工業與嵌入式領域,真正的數據金礦往往深埋在非視覺感測器之中,加速度計的震動波形、麥克風捕捉的環境音、馬達的三相電流數據,這些才是邊緣裝置最常處理的「語言」。
處理這些一維時序數據與處理二維影像有著本質上的不同,在影像辨識中,CNN會自動尋找物體或是人形的邊緣與紋理,但是到了訊號處理中,最關鍵的特徵往往隱藏在我們肉眼看不見的維度裡。
這一塊就是先前所說的DSP開始介入的時刻,以下進行簡易的說明:
- 時域的局限:客戶或開發者可能光看訊號隨時間變化的波形,很難區分正常的機器運轉聲與軸承磨損的初期雜訊,它們是被混在一起,看起來非常的雜亂。
- 頻域的透視:工程師必須利用FFT將訊號從時域轉換到頻域,這就像將一杯混合果汁還原成原本的水果成分,在頻譜圖上,一個微小的5kHz peak,可能就是設備故障的早期預警。
對於嵌入式 AI 來說,懂得如何對原始數據進行預處理,會比選擇哪種神經網絡架構更為關鍵。
模型裁剪
一旦我們完成了特徵工程,下一步就是開始建構客製化模型,但如前所述,直接將標準模型部署到 MCU 是不可行的,我們必須對模型進行調整跟手術,而這種技術上會被稱為模型裁剪。
像是人類大腦在成長過程中,也會修剪掉那些不常用的神經突觸,以強化常用的連結,從而提高效率,在人工神經網絡中,原理是一樣的:
- 稀疏化:訓練完畢的模型中,會有許多權重參數其實非常接近零,或者對最終輸出的影響微乎其微。
- 移除冗餘:裁剪技術就是識別並移除這些無用吃閒飯的神經元連結。
- 結果:在經過激進裁剪的模型,其參數量可能減少 50% 甚至 90%,但準確率卻幾乎不變,這也就意味著原本需要佔用 500KB Flash 的模型,現在可能只需要 50KB,這直接決定了專案能否使用更低成本的 MCU,像是Renesas MCU RL78 或是RA2系列產品。
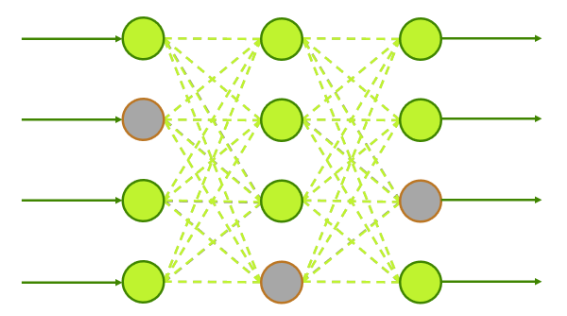
量化:從浮點數回歸成整數
除了減少參數數量,我們還必須降低每個參數的精度成本,在雲端伺服器上,運算通常使用 32bit 浮點數來確保極致的精確度。
然而,大多數低功耗 MCU 並不配備強大的浮點運算單元,或者處理浮點數會消耗過多的時鐘週期與電力。
量化技術模型中的權重與激活值,從32bit浮點數映射到8bit整數(FP32->int8)。
- 得到的效益:記憶體佔用會直接砍到剩下四分之一,且 MCU 的整數運算單元處理速度遠快於浮點運算。
- 面臨的挑戰:這是一個有損壓縮的過程,如何在降低精度的同時,確保模型不會因為捨入誤差而產生誤判,是量化技術目前最大的難點。
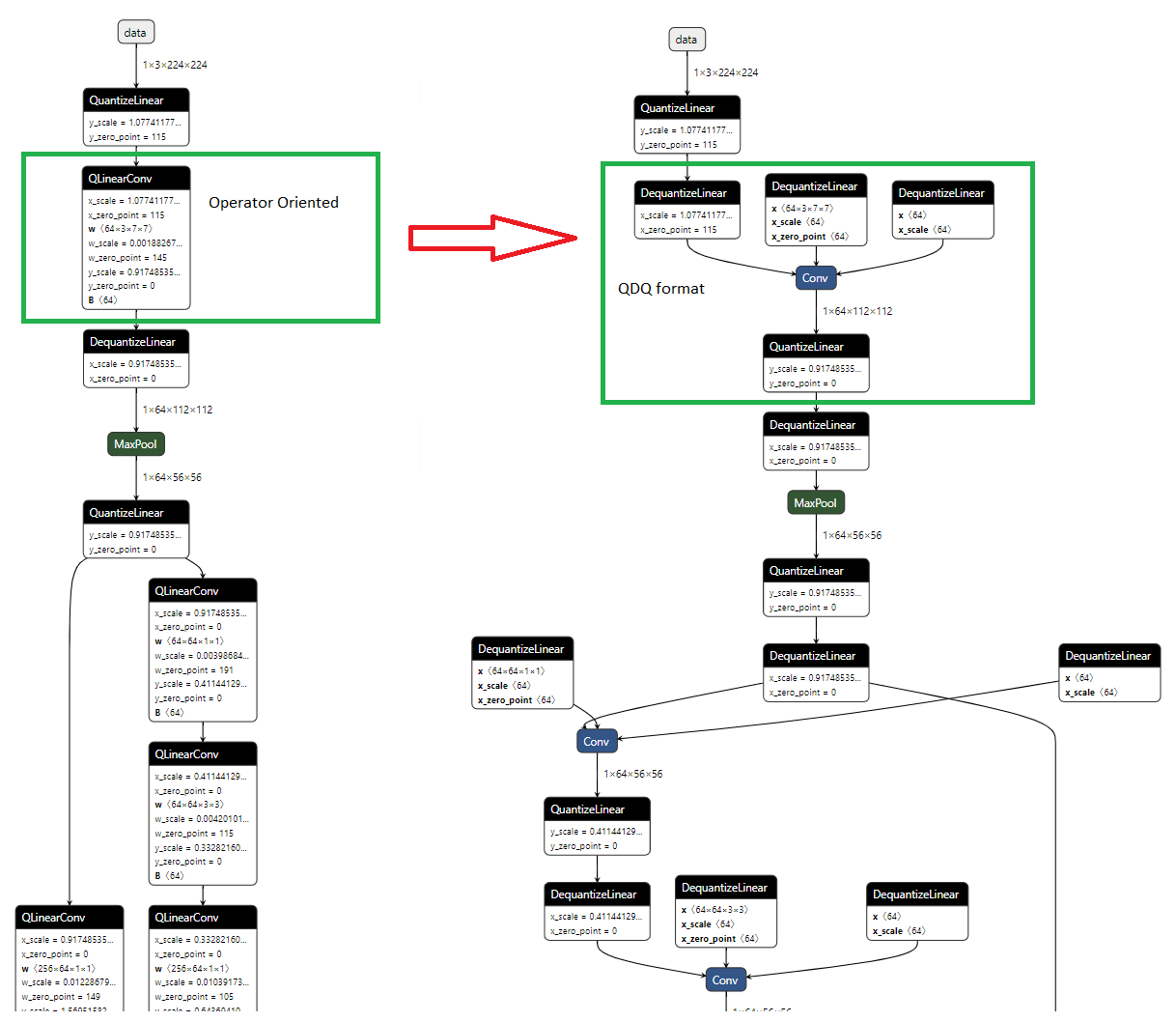
開發者遇到的手動優化的無底洞
理論上,上述無論是DSP 轉換、特徵選取、模型裁剪與量化都是可行的標準工法,但在現實專案中,要完美執行這些步驟卻是一個巨大的資源黑洞。
試想一下,當一位韌體工程師面對著一組或是大量充滿雜訊的馬達震動數據:
- 他需要像資料科學家一樣,不斷嘗試各種濾波器與 FFT 參數,試圖找出特徵。
- 他需要像演算法工程師一樣,手動調整神經網絡架構,反覆訓練、裁剪、驗證,尋找準確率與模型大小的平衡點。
- 最後,他還需要手寫C語言程式,將這個Python模型移植到MCU上,並確保記憶體沒有溢出。
這種手動特徵工程以及試錯式模型調校不僅效率低落,而且極度依賴工程師的個人經驗,往往一個參數設錯,就會導致模型在實驗室的測試報告表現完美,一上線就發生失效的情形。
這正是目前產業中迫切需要Renesas Reality AI 的原因,我們需要的不是更多的手動工具,而是一個能自動幫我們完成資料分析到模型生成的智慧嚮導。
三、如何使用Renesas Reality AI解決開發中時間成本的問題
自動化特徵資料探索
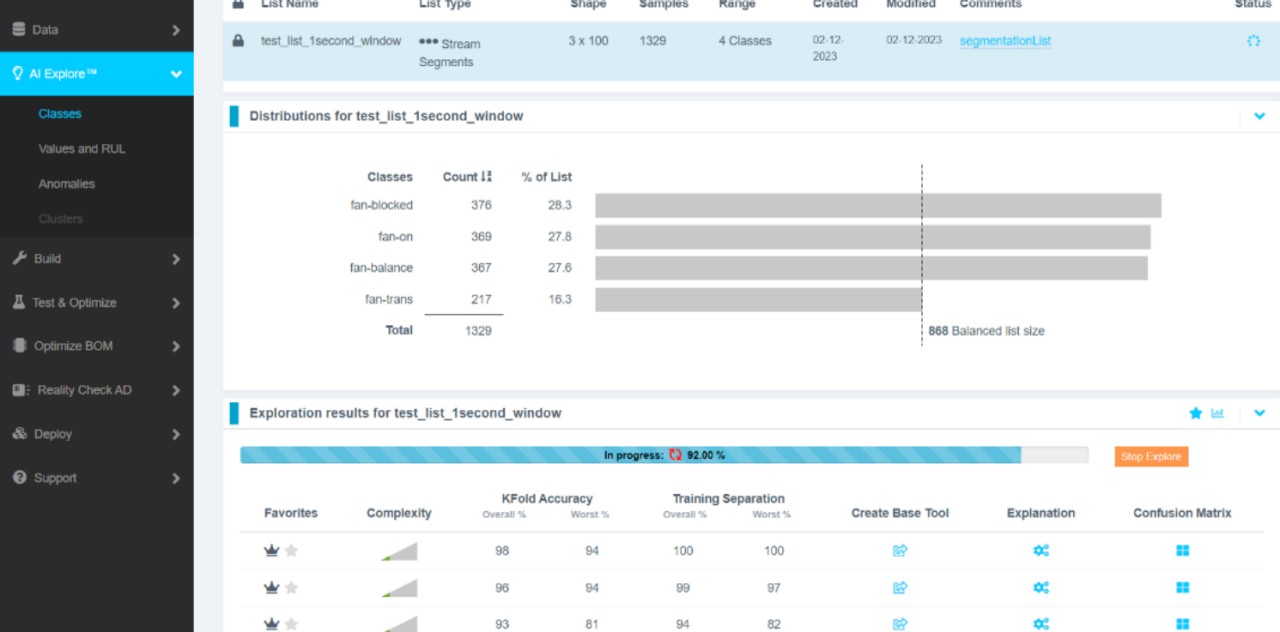
在前面,我們提到了手動尋找訊號特徵就如同大海撈針,然而Renesas Reality AI Explorer徹底改變了這個遊戲規則,它採用了一種很獨特的方法使用 AI 來構建 AI。
不同於傳統深度學習依賴龐大神經網絡來隱性地吸收特徵,Reality AI 採用了高維度特徵空間搜索技術,當你輸入原始的感測器數據,像是加速度計震動或電流波形時,Reality AI Tool會自動生成數千種可能的特徵組合,其中涵蓋時域統計量、頻域譜線、時頻分析等多種 DSP 轉換。
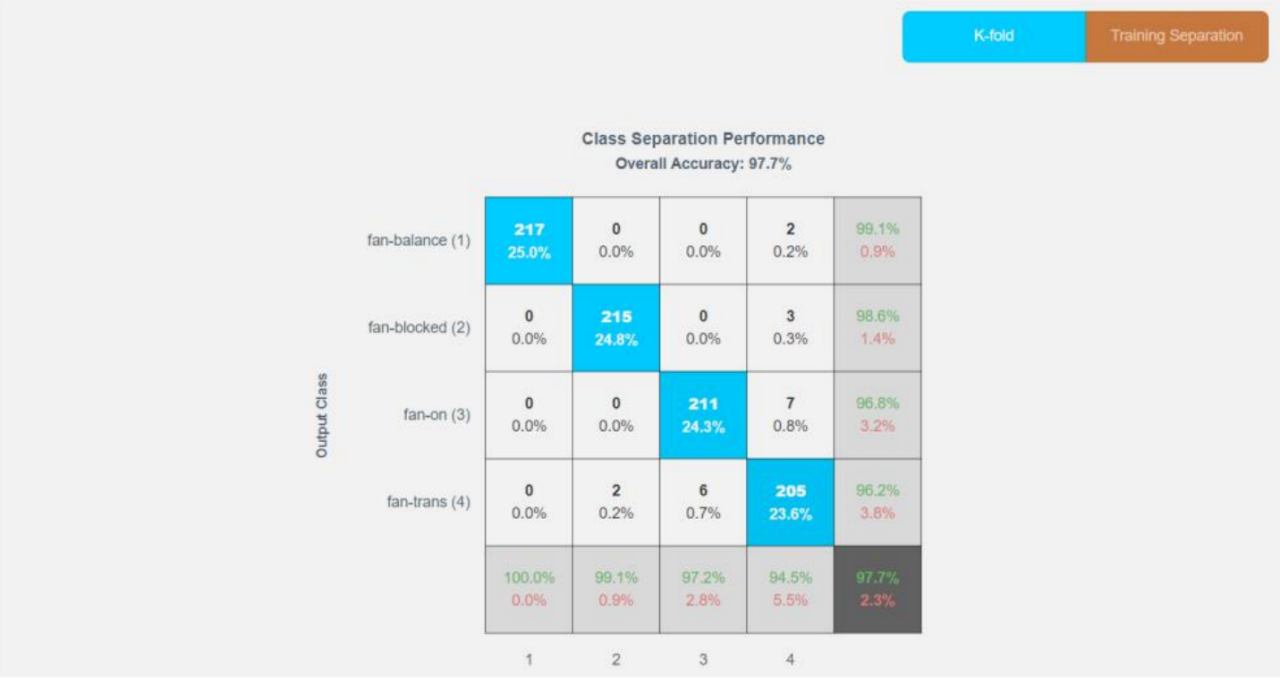
接著,系統會利用數學演算法,去自動評估這些特徵對目標分類,像是”轉軸平衡”vs”轉軸不平衡”的貢獻度,這實際上是一種極致的資料裁剪過程,系統會自動拋棄那些無效、冗餘或雜訊過多的數據維度,只保留那幾個最關鍵、最具辨識力的訊號特徵。
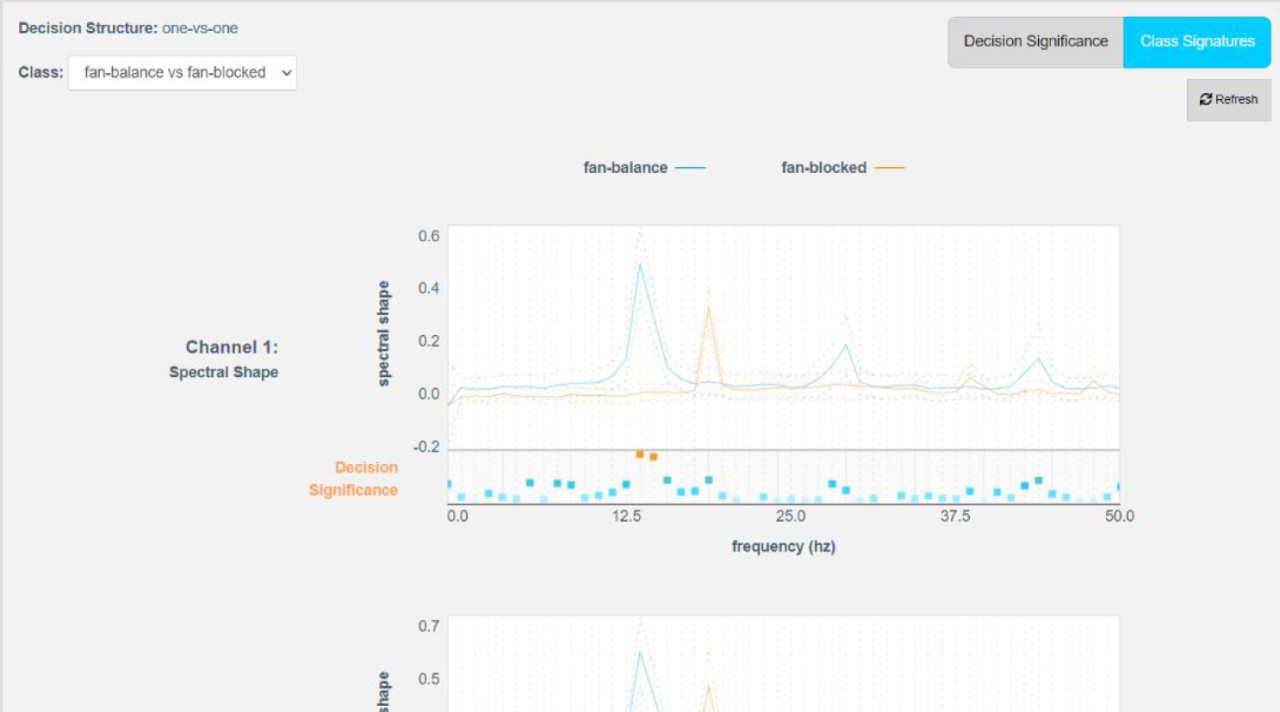
這意味著,開發者不再需要具備深厚的訊號處理博士學位,Reality AI 會告訴你對於這個馬達故障偵測任務,觀察2.5kHz的頻率震幅變化,會比看整體波形更有效。
硬體感知的模型生成
找到特徵只是第一步,如何將其轉化為能在MCU上運行的程序才是其中的關鍵,這裡體現了 Reality AI 與一般開源 AI 框架最大的不同,它是屬於硬體感知的。
當你在 Reality AI Tool中完成模型訓練後,它輸出的不是一個笨重的 TensorFlow Lite 檔案,而是一組高度優化的、輕量級的C語言函式庫。
- 原生適配:在新建專案時,可以選擇特定的裝置,而這些程式是專門為了 Renesas MCU的架構像是RA 系列的 Arm Cortex-M 核心、RX 系列的高效能核心,甚至是低階的16bit的RL78 系列所生成的。
- 極致裁剪:編譯器會根據選擇的目標晶片的記憶體限制(Flash/RAM),而自動調整模型的複雜度與運算邏輯,這也是一種自動化的模型瘦身,確保 AI 推論過程佔用的資源降至最低。
- 無縫整合:由於輸出的是標準C/C++程式,它可以直接整合進 Renesas IDE e²studio的開發環境中,與現有的韌體邏輯無縫接軌。
可解釋性的AI
在工業與車用領域,信任比準確更重要,傳統深度學習模型往往像是一個黑盒子,工程師無法解釋為什麼模型會判定設備故障。
而Reality AI 提供了完整的可解釋性,因為它是基於特定的物理特徵,如頻率、振幅、過零率等來建立模型,工程師可以清楚地追溯整體決策邏輯。你可以在儀表板上看到模型具體是依據哪一段頻譜的異常波動做出的判斷,這不僅讓除錯變得容易,也讓最終用戶敢於放心地採用 AI 判讀結果。
降低整體BOM的成本,提升商業價值
最終,這一切技術優勢都導向了一個核心商業價值,就是BOM 成本的極致優化。
透過 Reality AI 的高效能特徵萃取與模型裁剪,原本可能需要昂貴 MPU 或高階 MCU 才能執行的 AI 運算,現在可以在低成本、低功耗的中低階 MCU 上流暢運行。這一架構的轉變,意味著核心運算單元的開銷有機會大幅縮減 80% 至 90%。
這不僅為產品釋放出巨大的利潤空間,還同時帶來了更低的功耗與更長的電池壽命,讓您的產品在價格敏感的市場中擁有壓倒性的競爭力。
四、如何探索Renesas Reality AI Tools
賦予晶片感知的靈魂
在 AIoT 的時代,硬體不再是限制,思維才是
過去,我們往往會受困於晶片的物理規格,進而限縮了應用的想法,但是現在,透過 Renesas Reality AI這套工具,我們打破了這道藩籬,開發者的工作不再只是編寫冷冰冰的程式碼,而是在賦予 MCU 一種「感知物理世界」的真實本能。
當最基礎的微控制器也能從繁雜的訊號中「聽見」異常、「感覺」到震動,我們就不只是在製造電子產品,而是在創造具有洞察力的智慧夥伴。
這,才是嵌入式智慧真正的未來。
開啟您的 Reality AI 之旅
(1)Reality AI Tool:https://www.renesas.cn/zh/software-tool/reality-ai-tools#overview
參考資料
You may also want to know






Links
Follow us on Macnica Galaxy social media




©Copyright 2026 Macnica Galaxy Inc.