
進化AI電腦新視覺
AI(Artificial Intelligence)人工智慧意指是讓機器或是電腦可以展現出人類思維模式的技術。也因現今電腦儲存空間與GPU(Graphics Processing Unit)的大幅提升下,好讓演算法所需要依賴大量的數據與資料可透過由電腦分析與處理歸列出規則讓機器來學習,近幾年來攝影機大量使用、IoT(Internet of Things)與巨量通訊、智慧型手機、自駕車載系統、安全監控系統、物件辨識、臉部辨識…等資訊技術大幅進步下,AI也開始發展實際的應用在不同的領域。
近年來發展蓬勃的電腦視覺(Computer Vision),主要是來模擬人類視覺部分,是AI發展快速的領域其中之一,就是透過由攝影機來模擬視覺系統,可以使電腦擁有人類視覺能力的技術,簡單來說,經由影像感測器擷取到的影像,再這些影像資料庫透過由相關AI的演算法進行運算所得到的結果,去做分析及判斷到辨識,這可以在製造業、零售業甚至到醫療、金融等相關產業,來協助產品檢測、物體辨識與分類或者是人員與環境監控等…這些許多類似的應用上。
視覺資料處理技術已經出現一段時間,早期大部分流程序還是需人工介入,造成費時與容易出錯的狀況。如以前臉部辨識系統,人員必要手動標記關鍵資料點,標註數千張或是數萬張照片的人臉鼻樑的寬度與雙眼間距。自動化這些資訊需大量運算能力,因影像資訊非結構化難使用電腦來處理。但現今此領域的進展加上運算能力明顯提高,可以提高影像資訊處理的準確性與規模。現在電腦視覺系已採用雲端運算資源,每個人都能做存取。
電腦視覺概論
先簡單敘述AI框架(如圖一所示)簡意圖示,AI是一個巨大的集合,「機器學習」(Machine Learning)只是其中的集合之一,而「深度學習」(Deep Learning)更是「機器學習」(Machine Learning)的其中一個小集合。
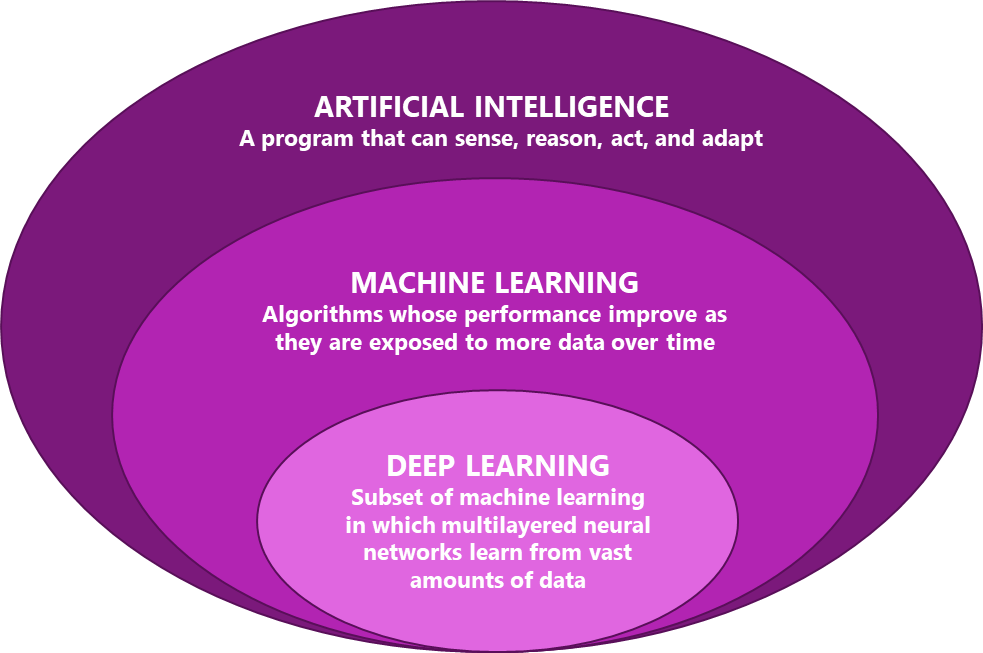 圖一
圖一
機器學習(Machine Learning)促進AI發展,與近年來深度學習(Deep Learning)發展的突破,更加推動AI的應用與爆發性發展。深度學習在人工神經網路(Artificial Neural Network)的基礎上,發展出多層次模型如深度神經網路(Deep Neural Networks, DNN)、卷積深度神經網路(Convolutional Neural Networks, CNN)等數種框架,可以處理更抽象與更加複雜的識別與分類,例如:討論熱烈的自動駕駛(Self-driving automobile)領域就是在電腦視覺方面有成功的應用之一。
電腦視覺這個領域也是近來深度學習(Deep Learning)最為快速發展的一塊,包括上述提到的自動駕駛之外還有智慧家居、生產品瑕疵的檢測、安防監控、醫療影像相關應用,都與深度學習(Deep Learning)影像辨識技術息息相關。
在描述電腦視覺領域的幾種任務之前,先說明電腦視覺中最為基本的部分『圖像』。圖像最重要的部分稱為像素(Pixel),即為圖像顯示的基本單位,每一個小方格會有一個明確位置、單一的色彩與光的強度,而圖像即為數百個甚至到數千萬個像素集合而成(如圖二所示)簡意圖示。
 圖二
圖二
說明完圖像定義現即回歸簡述電腦視覺領域圍繞的幾種任務,這些任務包含:圖像分類、目標跟蹤、物體辨識、語義分割、實例分割、圖像生成、關鍵點檢測、場景文字辨識、影像分類、度量學習等,分別如下簡述說明:
圖像分類
圖像分類是電腦視覺重要的基礎問題,即依據圖像特徵描述,對於不同類別圖像進行分類,分類演算透由手動輸入特徵或特徵學習,對圖像全區域描述判斷是否存在某種物體。分類流程為給一組被標記並是單一類別的圖像,對新圖像類別進行預測。是其他高階視覺的基礎如圖像分割、行為分析、物體跟蹤、物體檢測、人臉辨識等。並在深度學習的助益推動下,大幅度提高圖像分類的準確率。常使用的方式為卷積深度神經網路(Convolutional Neural Networks, CNN),基本結構是由卷積層、池化層以及全連接層組成。圖像輸入卷積深度神經網路經由卷積層做特徵提取,再由池化層過濾細節,在全連接層進行特徵展開,再提供給分類器取得分類結果。在圖像分類訓練常用的有 LeNet-5、AlexNet(如圖三所示框架)、GoogLeNet、preResNet、ResNet、ResNeXt、VGG-16/19、DenseNet、Inception-V3/V4、SENet、MobileNetV2 等這些模型。
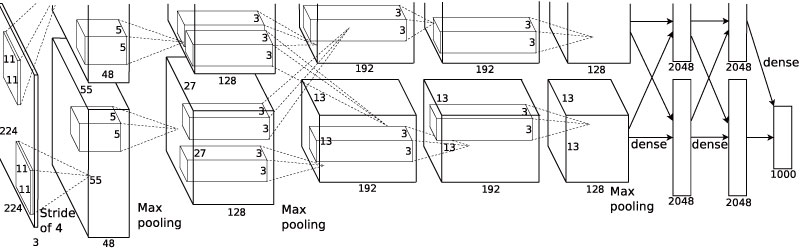 圖三
圖三
Figure 2: An illustration of the architecture of our CNN, explicitly showing the delineation of responsibilities between the two GPUs. One GPU runs the layer-parts at the top of the figure while the other runs the layer-parts at the bottom. The GPUs communicate only at certain layers. The network’s input is 150,528-dimensional, and the number of neurons in the network’s remaining layers is given by 253,440–186,624–64,896–64,896–43,264– 4096–4096–1000
目標跟蹤
在場景中跟蹤想了解物件或是多物件的過程。即是目標物在跟蹤影像的第一個幀(Frame)的初始狀態(如位子、尺寸) ,後續自動預估目標物的狀態。基於卷積深度神經網路的訓練常用的有FCNT和MD Net。
物體辨識
物體辨識主要是提供一張圖像或是一個影像,讓電腦找出所有物體所在的位置並提供出每個物體的類別。物體辨識任務訓練常用的包括 R-CNN、Faster R-CNN)、YOLO(You Only Look Once) (如圖四所示框架)、SSD、R-FCN等這些模型。
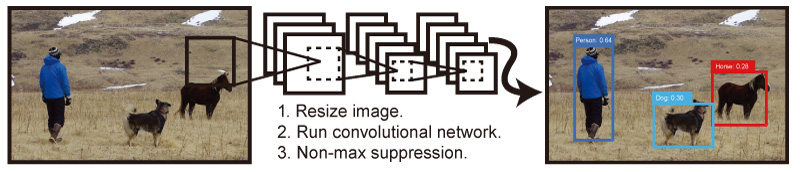 圖四
圖四
Figure 1: The YOLO Detection System. Processing images with YOLO is simple and straightforward. Our system (1) resizes the input image to 448 × 448, (2) runs a single convolutional network on the image, and (3) thresholds the resulting detections by the model’s confidence.
語義分割
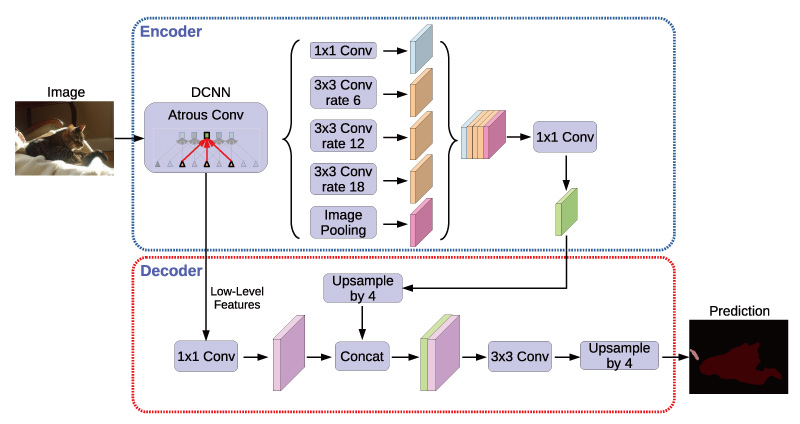 圖五
圖五
Our proposed DeepLabv3+ extends DeepLabv3 by employing a encoderdecoder structure. The encoder module encodes multi-scale contextual information by applying atrous convolution at multiple scales, while the simple yet effective decoder module refines the segmentation results along object boundaries.
實例分割
要對圖像中不同的物體做作分類,並且需確定物體之間的邊界、關係與差異性。其為是物體辨識加上語義分析的結合體。典型的模組為Mask R-CNN(如圖六所示框架)。
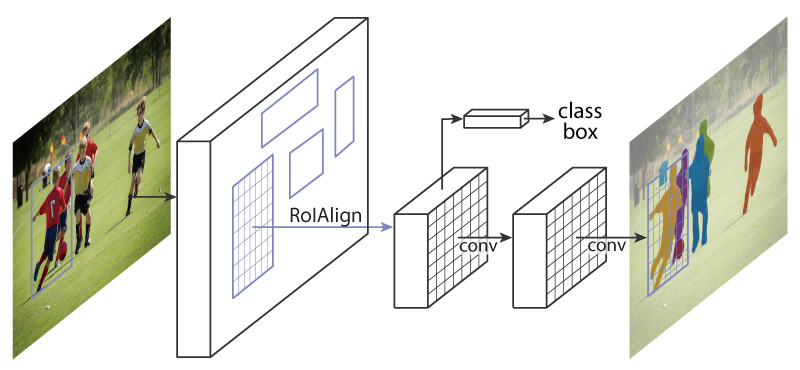 圖六
圖六
Figure 1. The Mask R-CNN framework for instance segmentation.
圖像生成
意指依照輸入的向量,產出目標圖像。應用的場景有人臉合成、圖像修復、手寫生成等。
關鍵點檢測
這類應用主要是偵測人體各部位,通過人體key point組合與追蹤辨識人類運動與行為,是很重要的應用在預測人體行為與描述人體姿態。模型包括OpenPose(如圖七所示框架)、coco2018。
 圖七
圖七
Top: Multi-person pose estimation. Body parts belonging to the same person are linked, including foot keypoints (big toes, small toes, and heels). Bottom left: Part Affinity Fields (PAFs) corresponding to the limb connecting right elbow and wrist. The color encodes orientation. Bottom right: A 2D vector in each pixel of every PAF encodes the position and orientation of the limbs.
場景文字辨識
有些場景的圖像背景複雜、解析度低、又有或多或少的文字訊息與多樣字體情形下,將圖像資訊轉為文字序列的過程,這類任務有使用CRNN-CTC 模型等。
影像分類
影像分類與圖像分類不同,不是靜止圖像是由多幀(Frame)圖像建構的,需要更多資訊才能理解相對的影像,在影像分類使用模組有Attention LSTM、NeXtVLAD、StNet、Temporal Segment Network (TSN) 等。
度量學習
也可稱為相似度學習或是距離度量學習,應用在人臉辨識/驗證、圖像檢索等有好的性能,此部分以Fluid 的深度度量學習模型。
電腦視覺的應用領域
電腦視覺能廣泛應用在各個產業類別方面,如智慧城市、智慧家庭、自駕車、機器人、科技執法、工業、醫療、消費等。例如:在生活中,即可常看到的機器人技術、自動駕駛和車牌辨識系統(停車場的智能管理),工業方面的智慧工廠。
機器人技術是使用機器人如自主移動機器人-AMR (Autonomous Mobile Robot),應用在搬運物品、掃地機器人或是無人機在環境中移動,這就需要用到多種視覺技術和同時定位與地圖構建(Simultaneous localization and mapping簡稱SLAM),而SLAM是機器人技術的演算之一,利用攝影機的影像資料來反映周圍環境,以及在未知環境中的位置。將SLAM與CNN一同使用,即可讓機器人對其未知環境下更為靈敏。
自動駕駛使用電腦視覺可以提供自駕車多樣功能,例如:行人與車輛檢測、車道線與交通號誌和標誌辨識、障礙物檢測等。透過由車上攝影機數量需求增加與解析度的提高並使用雷達和激光雷達等其他感測器,可即時確認周遭環境的資料數據,進行圖像識別和特徵提取等相關處理,讓自駕車在對於周遭環境有明確清晰的認知。例如:車道辨識透過由抓取車道線的特徵,對於直線與曲線進行處理,使自駕車能辨別出並可以依照正確車道駕駛。
車牌識別系統(Vehicle License Plate Recognition,VLPR)(如圖八)是將移動的車牌照從背景中辨識出來,透過由特徵提取、字元識別、圖像處理等技術,可以辨識出車輛號碼、顏色這些訊息。而車牌辨識除了應用在停車場管理外也有在高速公路收費、交通執法、車輛監控等各種場合。
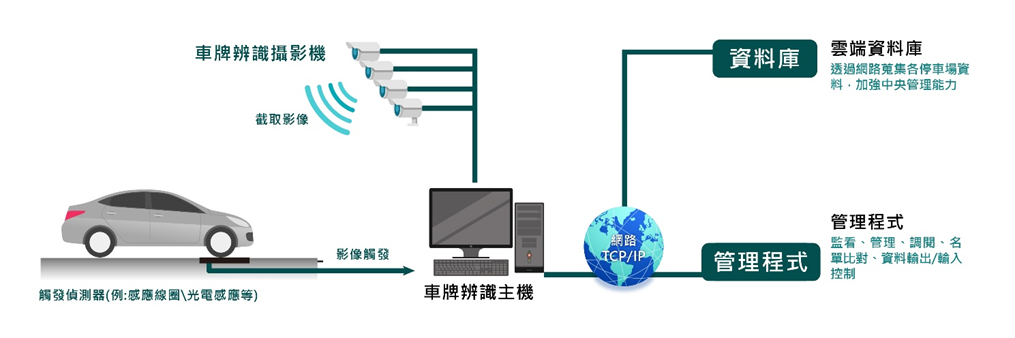 圖八
圖八
電腦視覺在智慧工廠(如圖九)中可以做到視覺檢測運用深度學習、3D影像重建即可以符合動態與模糊不清的影像檢測,物件辨識可以辨識飲料是否有異物且透過光學文字辨識(OCR)來確認日期是否正確,員工狀態監控可以辨識員工工作狀態與是否有異常動作也可以檢測身上安全裝備等,廠房安全監控可以設置電子圍籬以防人員進入可以即時停止設備與警告聲響提高工作領域安全性。
在智慧工廠中視覺檢測、物件辨識與廠房安全監控實際應用上我司已有客戶利用onsemi image sensor搭配Inter FPGA製作成3D掃描器,在產線可以提供機器手臂最完整的物件線索,達到簡易的物件辨識取物,也能在產線流線上做到簡易的視覺檢測。至於廠房安全監控方面也有客戶使用onsemi image sensor來做電子圍籬,設在機器手臂周圍當有人員靠近警戒區即發出警示並即時停止機器手臂警告人員已經進入到手臂迴轉半徑,提高廠房工作安全。
透由影像辨識智慧化技術協助人事物進行自動辨識是電腦視覺發展的方向,未來各項技術的突破預期會有更多應用導入電腦視覺,創造出更適合應用在智慧影像處理系統並視為共同的大目標。
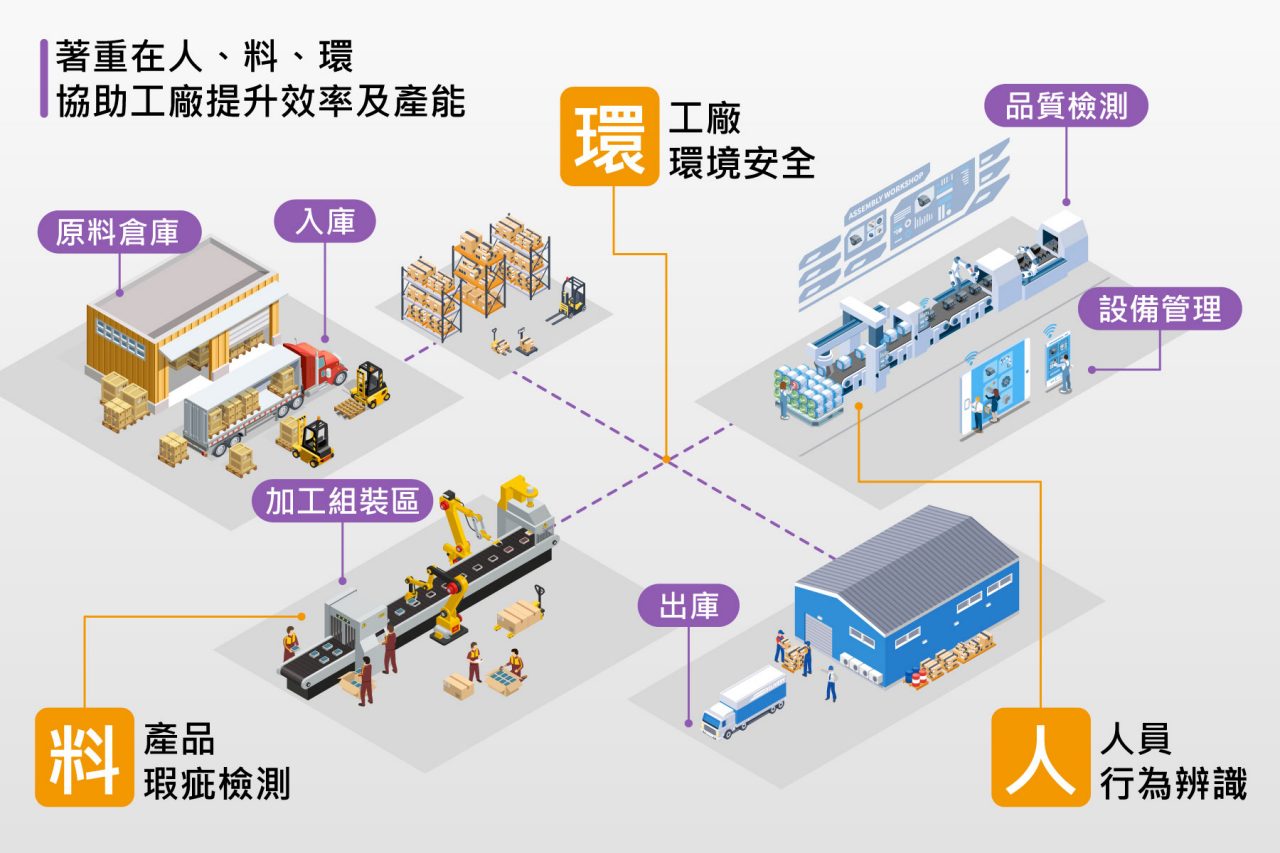 圖九
圖九
結論
茂綸代理的產品線之一onsemi有完整的產品架構,包含電源方案、類比方案、智慧感知等事業群。在電腦視覺應用中所應到的如智慧城市、自駕車、科技執法、人臉辨識、工業中的檢測等等這些應用都是在onsemi智慧感知所著重的部分,因此搭配nVIDIA GPU(Graphics Processing Unit),即可以提供完善的電腦視覺解決方案。
nVIDIA有完整的方案提供選擇,對於不同環境的使用提供對應的優勢。在GPU內建AI的推理引擎,將新的APU (AI Processing Unit),VPU (Vision Processing Unit, 視覺處理器)以及NPU (Neural Processing Unit類神經網路處理器)加快AI的推理速度與影像處理,同時優化效能。
現今影像視覺技術越來越普遍化,在未來各產業的電子設備勢必會加入更多的電腦視覺功能,onsemi image sensor與nVIDIA GPU在競爭激烈的市場上,可提供相當優勢在產品設計建構上。
參考文獻
- https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf ImageNet Classification with Deep Convolutional Neural Networks
- https://arxiv.org/abs/1506.02640 You Only Look Once: Unified, Real-Time Object Detection
- https://arxiv.org/abs/1802.02611 Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- https://arxiv.org/abs/1703.06870 Mask R-CNN
- https://arxiv.org/abs/1812.08008 OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
- https://www.flickr.com/photos/194971192@N07/51910776255
You may also want to know






相關連結
追蹤我們的社群平台!




©Copyright 2026 Macnica Galaxy Inc.